[JAVA] JFrame 닫을때 이벤트
JFrame jframe = new JFrame();
…
jframe.addWindowListener(new WindowAdapter() {
public void windowClosing(WindowEvent e) {
System.out.println(“사용자 명령으로 종료합니다.”);
System.exit(0);
}
});
당신의 업무력 향상과 칼퇴를 돕는 블로그
[JAVA] JFrame 닫을때 이벤트
JFrame jframe = new JFrame();
…
jframe.addWindowListener(new WindowAdapter() {
public void windowClosing(WindowEvent e) {
System.out.println(“사용자 명령으로 종료합니다.”);
System.exit(0);
}
});
java 현재 날짜 알아내기
현재날짜시간
현재시간
private static String getTodayDateTime() {
cal = Calendar.getInstance();
StringBuffer today = new StringBuffer();
today.append(String.format(“%04d”, cal.get(cal.YEAR)));
today.append(String.format(“%02d”, cal.get(cal.MONTH) + 1));
today.append(String.format(“%02d”, cal.get(cal.DAY_OF_MONTH)));
today.append(” “);
today.append(String.format(“%02d”, cal.get(cal.HOUR_OF_DAY)));
today.append(String.format(“%02d”, cal.get(cal.MINUTE)));
today.append(String.format(“%02d”, cal.get(cal.SECOND)));
return today.toString();
}
java 파일의 수정한날짜 알아내기
File file = new File(“경로”);
Calendar cal = Calendar.getInstance();
cal.setTimeInMillis( file.lastModified() );
———-
// 파일의 수정시간 알아내기
public String getFileModifyDateTime(File f) {
try {
Calendar cal = Calendar.getInstance();
cal.setTimeInMillis(f.lastModified());
return getTodayDateTime(cal);
} catch (Exception e) {
e.printStackTrace();
return “알 수 없는 날짜”;
}
}
private String getTodayDateTime(Calendar cal) throws Exception {
StringBuffer today = new StringBuffer();
today.append(String.format(“%04d”, cal.get(cal.YEAR)));
today.append(“-“);
today.append(String.format(“%02d”, cal.get(cal.MONTH) + 1));
today.append(“-“);
today.append(String.format(“%02d”, cal.get(cal.DAY_OF_MONTH)));
today.append(” “);
today.append(String.format(“%02d”, cal.get(cal.HOUR_OF_DAY)));
today.append(“:”);
today.append(String.format(“%02d”, cal.get(cal.MINUTE)));
today.append(“:”);
today.append(String.format(“%02d”, cal.get(cal.SECOND)));
return today.toString();
}
[JAVA] 자바 아이피주소 가져오기, ipAddress 얻기
윈도우나 리눅스 등 운영체제와 상관없이 잘 동작한다.
|
public String getIpAddress() throws NullPointerException, Exception { |
64bit 컴퓨터에서 vba Private Declare코드 사용하기
64bit 컴퓨터에서는 Private Declare Function 이라는 텍스트가 빨간색으로 표시되는 오류가 있다.
이를 무시하고 강제로 실행하게 되면,
컴파일 오류입니다: 이 프로젝트의 코드를 업데이트해야 64비트 시스템에서 사용할 수 있습니다. Declare 문을 검토하고 업데이트한 다음 PtrSafe 특성으로 표시하십시오.
라는 에러가 발생한다.
– 문제해결
Declare 뒤에 PtrSafe 라는 문자열을 붙인다.
Private Declare Function => Private Declare Function PtrSafe
Private Declare Sub => Private Declare Sub PtrSafe
예를 들어,
Private Declare Function ShellExecute Lib “shell32.dll” ~ 이 에러가 날 경우
Private Declare PtrSafe Function ShellExecute Lib “shell32.dll” ~ 으로 수정할 것.
Public Declare Sub Sleep Lib “kernel32.dll” ~ 이 에러가 날 경우
Public Declare PtrSafe Sub Sleep Lib “kernel32.dll” ~ 으로 수정할 것.
jsp tomcat url-pattern (스프링 jsp 직접호출 방법)
url-pattern 은 web.xml 에 정의해도 되고, 서블릿 상단에서 어노테이션 방식으로 써도 된다. (@WebServlet(urlPatterns = {“/”}) 이렇게 쓴다. 여러 개 쓰려면 @WebServlet(urlPatterns = {“/aaa/*”, “/bbb/*”}) 처럼 쓰면 된다.)
골 때리는건 url-pattern 은 except(exclude)를 설정할 수 없다. match(include) 작동만 한다. 아주 골 때린다.
더구나 정규식도 먹히지 않는다. 정규식이 아니라, 아주 한정적인 와일드 카드만 먹힌다.
1. /로 시작하고 /* 로 끝나도록 쓰는 패스. (ex : /temppath/*)
2. *.확장자 : 확장자를 매칭한다. (ex : *.do)
3. / : 디폴트 서블릿이다.
4. 그 외 동치 매칭이다.
한 마디로 [a-z], \d{1-4} 이딴거 안된다. 아…
아무튼 “*.do” 보다는 “/” 이라고 쓰는 디폴트 서블릿으로 설정하는게 가장 낫다. (그래야 REST 방식의 깔끔한 주소가 될 수 있다) 이렇게 하면 jsp, jspx, html, htm, js, css 등을 제외하고는 서블릿으로 갈 것이다. web.xml 에 보면 기존 servlet-mappng 에 jsp, jspx 가 설정되어 있을 것이다. 때문에 jsp는 처리가 된다. html, htm, js, css 는 정적 파일이기 때문에 그대로 bypass한다.
참고) web.xml
<!– The mapping for the default servlet –>
<servlet-mapping>
<servlet-name>default</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
<!– The mappings for the JSP servlet –>
<servlet-mapping>
<servlet-name>jsp</servlet-name>
<url-pattern>*.jsp</url-pattern>
<url-pattern>*.jspx</url-pattern>
<url-pattern>*.htm</url-pattern>
<url-pattern>*.html</url-pattern>
<url-pattern>*.js</url-pattern>
<url-pattern>*.css</url-pattern>
</servlet-mapping>
javascript 윈도우 가운데 띄우기
var winTop = -1;
var winLeft = -1;
var winWidth = 500;
var winHeight = 500;
if (winWidth < 1) {
winWidth = 500;
}
if (winHeight < 1) {
winHeight = 500;
}
if (winTop < 0) {
winTop = Math.ceil((window.screen.height – winHeight)/2);
}
if (winLeft < 0) {
winLeft = Math.ceil((window.screen.width – winWidth)/2);
}
var requestUrl = “타겟파일주소.jsp”;
var sizeSpec = “top=” + winTop + “,left=” + winLeft + “,width=” + winWidth + “,height=” + winHeight;
var etcSpec = “location=no,titlebar=no,scrollbars=no,toolbar=no,status=no,menubar=no,resizable=no”;
window.open(requestUrl, “_blank”, sizeSpec + “,” + etcSpec);
[Eclipse] 이클립스 Ctrl+Shift+F 단축키로 포맷팅
이클립스에서 단축키 Ctrl + I 를 누르면 자동으로 들여쓰기가 정렬되고
Ctrl + Shift + F 를 누르면 포맷팅이 된다.
포맷팅 방식이 마음에 들지 않는다면,
이클립스 상단 메뉴의 WIndow – Preferences – (좌측 리스트의) Java – Code Style – Formatter
에서 수정 가능하다.
New 버튼을 눌러 새로운 포맷팅을 만들 수 있다.
개인적으로 포맷팅만 하면 소스가 줄 바꿈 되어 엉망이 되는 것이 불만이었다.
1. 상단 탭의 Line Wrapping – Maximum line width 를 8000 으로 조정.
2. 상단 탭의 Comments – Maximum line width for comments 를 8000 으로 조정.
이제 줄 바뀜은 일어나지 않을 것이다.
함수/메서드, 클래스/인스턴스, 웹서버/와스, 추상 클래스/일반 클래스/인터페이스
1. 함수와 메서드의 차이
함수는 객체와 관련이 없는 함수다. 메서드는 객체에 속해있는 함수다.
그래서 자바는 메서드 라고 하고, 자바스크립트나 베이직같은 스크립트 언어에서는 함수라고 한다.
(물론 자바스크립트에서도 객체와 메서드를 만들 수 있다.)
2. 클래스와 인스턴스의 차이
클래스는 객체의 설계도이고, 인스턴스는 메모리 할당된(new 처리한) 객체다.
1개의 클래스를 토대로 n개의 인스턴스가 만들어질 수 있음.
3. 웹서버와 와스의 차이
웹서버는 정적 파일(html, 이미지, js)을 그대로 전달 해주고,
와스는 동적 파일(jsp)을 컴파일 처리한다.
웹서버의 대표적인 예로 아파치가 있고, 와스의 대표적인 예로 톰캣이 있다.
jsp 프로젝트를 실행할 때 톰캣으로 돌릴 수도 있고 아파치 + 톰캣으로 돌릴 수도 있는데,
둘 다 똑같이 돌지만 성능에 차이가 있다.
전자는 아파치가 html, 이미지, js를 처리하고 톰캣이 jsp를 처리한다.
후자는 톰캣 혼자 html, 이미지, js, jsp를 처리하니까 살짝 더 느리겠지.
4. 추상 클래스와 일반 클래스의 차이
추상 클래스는 구현되지 않은 메서드(=추상 메서드)가 1개 이상 존재한다.
일반 클래스는 모든 메서드가 구현되어 있다.
5. 추상 클래스와 인터페이스의 차이
추상 클래스는 어디까지나 클래스다. 상속 가능하다.
추상 클래스는 구현되지 않은 메서드와 구현된 메서드가 같이 존재할 수 있다.
인터페이스는 구현되지 않은 메서드만 갖고 있다. 클래스가 아니므로 상속(익스텐즈)이 불가능하고, 대신, 구현(임플리먼트) 가능하다.
자바는 다중 상속이 지원되지 않는 한편 인터페이스를 지원한다. (다중 상속의 장점만을 취함)
인터넷 익스플로러 항상 새 세션으로 띄우기
개발 작업하다 보면 여러 아이디로 테스트를 동시에 해야할 때가 많은데, 이럴 때 세션 꼬이지 않게 새 세션 띄우기를 해야한다.
내가 원래 사용하던 방법은,
1. 익스플로러 상단 메뉴의 ‘파일(F)’ – ‘새 세션(I)’ 으로 창 띄우기.
이 방법은 기존의 띄워져 있는 창을 굳이 찾아야 한다는 점이 불편하다. 항상 익스플로러가 새 세션이라는 보장도 없다.
새로운 방법은,
1. 익터넷 익스플로러 바로가기 아이콘 위에서 마우스 우클릭 – 속성 – 바로가기 탭 – 대상(T) 인풋박스 부분 맨 뒤에 -nomerge 라고 써준다.
이 때 바로가기 아이콘마다 다르게 적용되므로 바탕화면 바로가기, 작업표시줄의 바로가기 등 일일히 기입해 넣어줘야 한다.
한 번만 해두면 앞으로 해당 바로가기로 실행되는 익스플로러는 항상 새 세션이니 좋다.
세션을 유지하고 싶을 때는 윈도우가 이미 떠있는 상태이므로, 메뉴 – 새 창, 메뉴 – 탭 복제를 쓰면 되고. (단축키 : Ctrl + N(새 창), Ctrl + K (탭 복제))
레지스트리 값을 변경하는 방식도 있는데 그냥 바로가기 뒤에 -nomerge 주는게 낫다.
이거하자고 레지스트리 값 변경할 것 까지야 없다고 본다.
[mysql] Error Code: 1175. You are using safe update mode
mysql 에서 테이블을 삭제하려고 할 때(delete from 테이블명) 아래처럼 에러 발생.
Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column
To disable safe mode, toggle the option in Preferences -> SQL Editor and reconnect. 0.000 sec
SQL 에디터에서
SET SQL_SAFE_UPDATES=0; 을 쿼리 실행하면 된다.
배치(bat) 또는 쉘(sh) 실행하는 자바 코드 (190214 수정)
실행되었을 때 터미널 창에 찍히는 값을 가져올 수 있다.
ProcessBuilder processBuilder = null;
Process process = null;
try {
String osType = “window”;
// String osType = “unix”;
String filePath = “”;
if (osType.toLowerCase().indexOf(“window”) > -1) {
processBuilder = new ProcessBuilder(“CMD”, “/c”, filePath /* 배치 파일 경로 */);
} else {
processBuilder = new ProcessBuilder(“sh”,filePath /* 쉘 파일 경로 */);
}
processBuilder.redirectErrorStream(true);
process = processBuilder.start();
BufferedReader br = new BufferedReader(new InputStreamReader(process.getInputStream()));
String line = null;
while ((line = br.readLine() ) != null) {
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
예제로 bat 파일을 만들고 싶다면 아래와 같이 작성해서 bat확장자로 저장하면 된다.
@echo off
echo 첫 번째 라인
echo 두 번째 라인
echo next line
echo bye
lpad는 좌측부터 자리수만큼 숫자 채우기, rpad는 우측부터 자리수만큼 숫자 채우기하는 SQL 함수 이름이다.
해당 기능의 함수를 따로 만들어쓰는 편인데, 귀찮다면 내장되어 있는 String.format 함수를 쓰면 된다.
String.format(“%06d”, 999);
== > 000999 가 된다.
응용해서 쓰면 됨.
예제 (오늘 날짜 가져오기)
cal = Calendar.getInstance();
StringBuffer today = new StringBuffer();
today.append(“#”);
today.append(String.format(“%04d”, cal.get(cal.YEAR)));
today.append(“/”);
today.append(String.format(“%02d”, cal.get(cal.MONTH) + 1));
today.append(“/”);
today.append(String.format(“%02d”, cal.get(cal.DAY_OF_MONTH)));
today.append(” “);
today.append(String.format(“%02d”, cal.get(cal.HOUR_OF_DAY)));
today.append(“:”);
today.append(String.format(“%02d”, cal.get(cal.MINUTE)));
today.append(“:”);
today.append(String.format(“%02d”, cal.get(cal.SECOND)));
today.append(lineSeperator);
C에 대해서는 아는 바가 없어서 상무님께 여쭤보고 간단하게 기록해둔다.
자바 클래스는 jd gui 등으로 디컴파일을 해서 열어볼 수 있는데, c는 그럴 수 없는지 궁금했다.
컴파일할 때 뒤에 -d 옵션을 주면 디버그를 할 수 있도록 컴파일된다.
만약 해당 옵션을 주지 않는거나, 일반적인 컴파일일 경우에는 해당 파일을 GDB 로 디버그하며 쫓아갈 수 있다. 컴파일된 파일이 관련된 링크의 어드레스 정보를 갖고 있기 때문이다.
상용 배포하는 프로그램이라면 이러한 디컴파일, 디버그가 안되기를 바랄 것이다. 그럴 때 컴파일된 파일에 스트립 명령을 주면 된다.
기존 컴파일된 파일의 바이너리가 상당히 큰데, 이렇게 스트립 명령을 주면 바이너리가 확 줄어든다. 링크 어드레스 정보를 지우기 때문이다.
과거에 mfc 프로그래밍을 할 때 mfc42.dll 이라는 파일이 필요했는데, mfc 내부 로직이 어떻게 돌아가나 궁금할 수가 있다. 그럴 때 mfc42d.dll 파일을 system32 폴더 밑에 갖다놓고 돌리면 로직을 쫓아갈 수 있었다. mfc42.dll 파일은 스트립된 파일이고, mfc42d파일은 디버그용으로 컴파일 시킨 파일이다.
오라클 힌트(oracle hint)
오라클 힌트란?
1) 개요
힌트는 SQL 튜닝의 핵심부분으로 일종의 지시구문이다. SQL에 포함되어 쓰여져 Optimizer의 실행 계획을 원하는 대로 바꿀 수 있게 해준다. 오라클 Optiomizer라고 해서 항상 최선의 실행 계획을 수립할 수는 없으므로 테이블이나 인덱스의 잘못된 실행 계획을 개발자가 직접 바꿀 수 있도록 도와주는 것이다.
사용자는 특정 SQL 문장에서 어떤 인덱스가 선택도가 높은지에 대해 알고 있는데 이 경우 오라클 서버의 Optimizer에 의존하여 나온 실행 계획보다 훨씬 효율적인 실행계획을 사용자가 구사할 수 있다.
2) 사용법
힌트를 사용하여 아래와 같은 것들을 할 수 있다.
액세스 경로, 조인 순서, 병렬 및 직렬처리, Optiomizer의 목표(Goal)를 변경 가능
3) 형태
SQL 문장 내에 “/*+ 힌트내용 */”이 추가된다.
주의! 주석 표시에 더하기(+)가 있다.
예1)
SELECT /*+ index( idx_col_1 ) */
name, age, hobby
FROM member
예2)
INSERT /*+APPEND*/ INTO TEST00 …
예3)
INSERT /*+PARALLEL*/ INTO TEST00 …
| INDEX ACCESS OPERATION 관련 HINT | ||
| HINT | 내용 | 사용법 |
| INDEX | INDEX를 순차적으로 스캔 | INDEX(TABLE명, INDEX명) |
| INDEX_DESC | INDEX를 역순으로 스캔 | INDEX_DESC(TABLE명, INDEX명) |
| INDEX_FFS | INDEX FAST FULL SCAN | INDEX_FFS(TABLE명, INDEX명) |
| PARALLEL_INDEX | INDEX PARALLEL SCAN | PARALLEL_INDEX(TABLE명,INDEX명) |
| NOPARALLEL_INDEX | INDEX PARALLEL SCAN 제한 | NOPARALLEL_INDEX(TABLE명,INDEX명) |
| AND_EQUALS | INDEX MERGE 수행 | AND_EQUALS(INDEX_NAME, INDEX_NAME) |
| FULL | FULL SCAN | FULL(TALBE명) |
| JOIN ACCESS OPERATION 관련 HINT | ||
| HINT | 내용 | 사용법 |
| USE_NL | NESTED LOOP JOIN | USE_NL(TABLE1, TABLE2) |
| USE_MERGE | SORT MERGE JOIN | USE_MERGE(TABBLE1, TABLE2) |
| USE_HASH | HASH JOIN | USE_HASH(TABLE1, TABLE2) |
| HASH_AJ | HASH ANTIJOIN | HASH_AJ(TABLE1, TABLE2) |
| HASH_SJ | HASH SEMIJOIN | HASH_SJ(TABLE1, TABLE2) |
| NL_AJ | NESTED LOOP ANTI JOIN | NL_AJ(TABLE1, TABLE2) |
| NL_SJ | NESTED LOOP SEMIJOIN | NL_SJ(TABLE1, TABLE2) |
| MERGE_AJ | SORT MERGE ANTIJOIN | MERGE_AJ(TABLE1, TABLE2) |
| MERGE_SJ | SORT MERGE SEMIJOIN | MERGE_SJ(TABLE1, TABLE2) |
| JOIN시 DRIVING 순서 결정 HINT | ||
| HINT | 내용 | |
| ORDERED | FROM 절의 앞에서부터 DRIVING | |
| DRIVING | 해당 테이블을 먼저 DRIVING- driving(table) | |
| 기타 힌트 | ||
| HINT | 내용 | |
| append | insert 시 direct loading | |
| parallel | select, insert 시 여러 개의 프로세스로 수행- parallel(table, 개수) | |
| cache | 데이터를 메모리에 caching | |
| nocache | 데이터를 메모리에 caching하지 않음 | |
| push_subq | subquery를 먼저 수행 | |
| rewrite | query rewrite 수행 | |
| norewrite | query rewrite 를 수행 못함 | |
| use_concat | in절을 concatenation access operation으로 수행 | |
| use_expand | in절을 concatenation access operation으로 수행 못하게 함 | |
| merge | view merging 수행 | |
| no_merge | view merging 수행 못하게 함 | |
출처 1 : http://blog.naver.com/youngram2/220639017128
출처 2 : http://iclickyou.com/845
출처 3 : http://blog.naver.com/wideeyed/80036376623
인덱스(index)에 대한 메모
(인덱스에 대해 잘 아시는 분은 댓글을 통해 지식을 공유해주시기 바랍니다. 모호한 부분에 대한 지적 부탁드립니다. 감사합니다.)
아직 초보 개발자라 잘은 모르겠지만 인덱스에 대해 아는 대로 메모해둔다.
인덱스는 사전의 색인이라고 번역한다. 말 그대로 뭔가를 더 빠르게 찾아주기 위한 역할을 하는데, 따라서 where 문과 order by 에 쓰이는 듯 하다.
먼저 Primary Key 는 인덱스를 주지 않아도 된다. PK는 이미 인덱스가 걸려있기 때문이다. 그러나 PK가 아니라면?
예를 들어서 user_id 라는, PK가 아닌 컬럼이 있다고 해보자. select * from table user_id = ‘admin’ 이런 식으로 가져오겠지. 이 때, 인덱스가 없다면 테이블의 모든 로우를 풀 서치 해야한다.
그런데 user_id 가 미리 정렬되어 있다면 어떨까? 첫 글자가 a인 구간만 돌고, b인 구간에 들어서면 반복문을 빠져나가면 된다. 내 생각엔 인덱스를 걸어두면, 해당 컬럼을 미리 정렬해두는 것 같다. 그리고 insert를 할 때 마다 정렬이 되면서 삽입되겠지.
그러니까 인덱스는 where 문에도 쓰이고, order by 에도 쓰이는 것 같다. 다른 곳에 또 쓰이는지는 아직 모르겠다.
어디에 또 쓰이는지는 아직 잘 모르겠다.
인덱스는 이런 식으로 만든다.
|
CREATE INDEX IDX_테이블명_인덱스명 ON 테이블명 |
목록 쿼리가 select * from table user_id = ‘admin’ 로 쓰이고 있다면 다음과 같이 만들면 되는 것 같다.
|
CREATE INDEX IDX_TABLE_USERID ON TABLE |
이 때, 아래와 같이 정렬 기준을 줘도 된다.
|
CREATE INDEX IDX_테이블명_컬럼명 ON 테이블명 |
정렬 순서는 DESC 라고 명시하지 않으면, 기본값은 무조건 ASC로 들어가는 것 같다.
이렇게 인덱스에는 이미 정렬 순서가 있기 때문에, 해당 인덱스를 타면 ORDER BY 를 주지 않아도 기본적으로 정렬되어 출력된다고 한다. (USER_ID DESC) 로 쓴 경우에는 사용자 아이디 내림차순으로 돌겠지.
where 문에 컬럼 두 개가 들어간다면 아래와 같은 방식으로 쓴다.
|
CREATE INDEX IDX_테이블명_인덱스명 ON 테이블명 |
NOPARALLEL 말고 다른 건 없을까? PARALLEL 을 쓰면 된다. 기본값은 병렬 처리를 하지 않는 NOPARALLEL 이다. 병렬처리에 대해서는 아직 잘 모르겠다. 다만, 아래와 같은 식으로 쓰는걸 확인했다.
|
CREATE INDEX IDX_테이블명_인덱스명 ON 테이블명 PARALLEL ( DEGREE 8 INSTANCES 1 ); |
이렇게 인덱스는 컬럼 1개 짜리, 2개 짜리, 3개 짜리 식으로 쓸 수 있기 때문에 (아직 4개 짜리는 보지 못했다.), 어떤 인덱스를 타냐에 따라서 효율이 달라진다. 그냥 select 를 하면 DB 옵티마이저가 인덱스를 자동으로 선택해주는 것으로 알고 있다. 이럴 때 여러 개의 인덱스 중 원하는 인덱스를 항상 타도록 만드는 문구가 힌트(Hint)다. 여러 줄 주석처럼 생겼지만(/* ~ */) 이게 힌트다.
|
select /*+ index( idx_col_1 ) */ name, age, hobby from member |
인덱스는 사전의 색인처럼 검색과 정렬을 빠르게 해준다. 그렇기 때문에 값이 0 아니면 1이라던가, 중복된 값이 많은 컬럼에는 사용해봤자 별 소용이 없다. 밸류 하나하나가 유니크한 컬럼에 쓰면 효과가 좋다.
마지막으로 인덱스를 써도 느릴 경우는?
첫째, 전체 데이터 수가 별로 없다면 인덱스를 써서 오히려 느릴 수가 있다. 풀 스캔이 더 빠른데 괜시리 인덱스 영역을 건너갔다 오는 것이기 때문이다.
둘째, DB 마이그레이션(기존 시스템의 데이터를 새 시스템에 옮기는 일)을 여러 번 수행한 경우에 느릴 수 있다. 한 마디로 n개의 컬럼을 insert했다가, delete했다가, insert했다가, delete 했다가… 식으로 반복하면 인덱스에 가비지 값이 많이 쌓이면서 효율이 느려지는 것 같다. 이럴 때 인덱스를 리빌드(Rebuild)하면 다시 속도가 빨라진다.
2016년 11월 29일 화요일 흑곰 씀.
(초보 개발자입니다. 인덱스에 대해 잘 아시는 분은 댓글을 통해 지식을 공유해주시기 바랍니다. 모호한 부분에 대한 지적 부탁드립니다. 감사합니다.)
오라클 숫자 뒤의 알파벳 의미 (오라클 i, g, c의 의미)
orcale 7 -> 8i -> 9i -> 10g -> 11g -> 12c
i : Internet의 약자. 응용프로그램 지원
g : Grid computing의 약자. 분산 네트워크를 통한 자원통합을 지원
c : Cloud computing의 약자. 데이터베이스 자체적으로 가상화를 지원
js 현재 브라우저가 IE(인터넷익스플로러)인지 확인하기
var agent = navigator.userAgent.toLowerCase();
if (agent.indexOf(“msie”) > -1 || agent.indexOf(“trident”) > -1) {
// 익스플로러임
} else {
// 익스플로러 아님
}
익스플로러 10까지는 msie 라는 단어가 들어있으면 익스플로러다.
11에도 적용이 되는데, 마이너 버전에 따라 msie 라는 단어가 들어가있지 않은 경우가 있나보다.
그럴 땐 trident 라는 단어로 찾으면 된다. trident 는 IE에서 쓰는 레이아웃 엔진의 이름이다.
크롬, 파이어폭스, 사파리를 찾으려면 각각
agent.indexOf(“chrome”) > -1
agent.indexOf(“firefox”) >-1
agent.indexOf(“safari”) >-1
이런식으로 찾으면 되겠다.
근데 크롬은 userAgent에 safari라는 단어가 포함되어 있더라.
그러므로 크롬 체크를 사파리 체크보다 우선순위로 해둬야겠지.
나야 크롬인지 아닌지 체크할 일이 없으니 문제 없지만 해당되는 분들은 잘 확인해볼 것.
인스톨 파일(셋업 파일) 디지털 서명 넣는 법
인터넷에서 파일을 다운받았는데, 이 프로그램의 서명이 손상되었거나 잘못되었습니다. 라고 나오는 경우가 있다.
프로그램의 사용자 입장이라면 다운받은 파일 위에서 1. 마우스 우클릭 – 2. 실행을 선택해서 실행하면 된다. 단, 이게 바이러스거나 랜섬웨어일 경우는 책임 못진다. 직접 만든 프로그램이 아니면 실행하지 않는걸 추천한다.

만약 프로그램의 제작자 입장이라면 디지털 서명을 입혀 보내야 한다.
완성된 install 파일(exe)에 서명을 입힐 수 있는 프로그램이 있다. signcode.exe 다.
1. 시작 – 실행 – signcode.exe 실행해서 하라는대로 진행하면 된다.

엑셀VBA 행높이 자동조절(Row AutoFit)
엑셀에서 row와 row 사이 경계선을 더블클릭하면 행높이가 자동조절된다. 명칭은 몰랐는데 이걸 AutoFit 기능이라고 하나보다.
vba에서 AutoFit을 실행하려면 아래와 같이 쓰면 된다.
‘1로우부터 5000로우까지 행높이 자동조절
Rows(“1:50000”).EntireRow.AutoFit
자바 정규식 기본정리 : Matcher, Pattern, find(), group()
정규식을 사용하면 문자열(String)이 특정 패턴과 일치하는지 여부를 확인하거나, 패턴에 맞는 값을 찾아내거나, 해당 값을 새로운 값으로 바꿀 수 있다.
이 방법이 일목요연하게 작성되어 있는 곳이 마땅히 보이지 않았기에 직접 정리해서 써본다.
1. matches (일치하는지 확인)
target 은 대상이 되는 문자열(문장)을 담는 변수이고, regEx는 정규식(Regular Expression) 을 담는 변수라고 해보자.
public void isEqualRegEx() {
String target = “나는 2008년도에 입학했다.”;
String regEx = “.*\\d{1}.*”;
// String regEx = “.*[0-9].*”; 와 동일함
if (target.matches(regEx)) {
System.out.println(“일치”);
} else {
System.out.println(“불일치”);
}
}
여기서 regEx 는 “.*\\d{1}.*”; 이다. 즉 여기서 target.matches(regEx) 는 숫자가 1개라도 포함되어 있느냐고 묻는 것이다.
(“.*” 는 모든 복수의 문자이고, “\\d{1}”는 한 자리 숫자이므로.)
이 경우 2008, 이렇게 숫자가 4개나 있으니까 당연히 “일치”가 출력되겠지.
만약 regEx 값이 바뀐다면 어떨까?
regEx == “.*\\d{1}.*” -> 일치
regEx == “.*[0-9].*” -> 일치 ([0-9]는 \\d{1} 와 정확히 같은 뜻임)
regEx == “.*[0-9][0-9][0-9][0-9].*” -> 일치 (숫자 4자리)
regEx == “.*[0-9][0-9][0-9][0-9][0-9].*” -> 불일치 (숫자 5자리)
regEx == “.*\\d{1,4}.*” -> 일치 (숫자 1자리 이상 4자리 이하)
regEx == “.*\\d{2,5}.*” -> 일치 (숫자 2자리 이상 5자리 이하)
regEx == “.*\\d{5,6}.*” -> 불일치 (숫자 5자리 이상 6자리 이하)
요런 식으로 되겠다.
2. replaceAll (패턴에 맞는 값을 새로운 값으로 치환)
public void replaceRegEx() {
String target = “나는 2008년도에 입학했다.”;
String regEx = “[0-9]”;
Pattern pat = Pattern.compile(regEx);
Matcher m = pat.matcher(target);
String result = m.replaceAll(“2”); // 패턴과 일치할 경우 “2”로 변경
System.out.println(“출력 : ” + result);
// 출력 : 나는 2222년도에 입학했다.
}
여기서 regEx 변수 값은 “[0-9]” 이다. 그러니까 위 소스는 1자리 숫자들을 “2”로 치환하게 된다.
결과는 당연히 “나는 2222년도에 입학했다.”가 된다.
위 함수를 3줄로 줄이면 아래와 같다.
public void replaceRegEx() {
String target = “나는 2008년도에 입학했다.”;
String regEx = “[0-9]”;
System.out.println(“출력 : ” + target.replaceAll(regEx, “2”));
}
String 객체에 replaceAll 라는 멤버함수가 있다. 이게 더 낫다.
전자는 Pattern 객체와 Matcher 객체를 추가로 임포트하는데, 후자는 String 객체만 있으면 되니까.
3-1. find(), group() (패턴에 맞는 값 1개씩 찾아내기)
요 find랑 group이라는 함수가 특이한데 Matcher 의 멤버함수다.
일단 단순무식한 코드로 배워보자.
public void findRegEx(){
String target = “나는 2008년도에 입학했다.”;
String regEx = “[0-9]”;
// 정규식(regEx)을 패턴으로 만들고,
Pattern pat = Pattern.compile(regEx);
// 패턴을 타겟 스트링(target)과 매치시킨다.
Matcher match = pat.matcher(target);
System.out.println(match.find()); // true
System.out.println(match.group()); // 2
System.out.println(match.find()); // true
System.out.println(match.group()); // 0
System.out.println(match.find()); // true
System.out.println(match.group()); // 0
System.out.println(match.find()); // true
System.out.println(match.group()); // 8
System.out.println(match.find()); // false
System.out.println(match.group()); // 에러 발생! (IllegalStateException)
}
Pattern에 compile로 정규식(regEx)을 담고, Matcher에 타겟 스트링(target)을 담는게 먼저다.
그 다음 Matcher의 find() 함수를 쓰면 1번째 값을 찾아내고, true 혹은 false를 반환한다.
group() 을 쓰면 방금 찾은 1번째 스트링이 튀어나온다.
다시 find()를 쓰면 2번째 값을 찾고, group()을 쓰면 2번째 값이 튀어나오고… 이런 식이다.
보면 2, 0, 0, 8 까지 잘 가다가 (숫자가 더 이상 없으므로 당연히) 5번째에서 에러가 나는데,
따라서 에러가 나지 않도록 코드를 쓴다면 아래와 같이 작성해야 마땅하겠다.
…(전략)…
if (match.find()) {
System.out.println(match.group());
}
…(후략)…
3-2. find(), group() (패턴에 맞는 값 모두 찾아내기)
3-1에서 설명한 바를 잘 정리한게 아래 메서드다.
public void findAllRegEx(){
String target = “나는 2008년도에 입학했다.”;
String regEx = “[0-9]”;
Pattern pat = Pattern.compile(regEx);
Matcher match = pat.matcher(target);
int matchCount = 0;
while (match.find()) {
System.out.println(matchCount + ” : ” + match.group());
matchCount++;
}
System.out.println(“총 개수 : ” + matchCount);
// 0 : 2
// 1 : 0
// 2 : 0
// 3 : 8
// 총 개수 : 4
}
보시다시피 while문을 사용해 find()가 false가 될 때까지 루프를 돌리면 된다.
끝. bb_ 2016-11-16 18:03
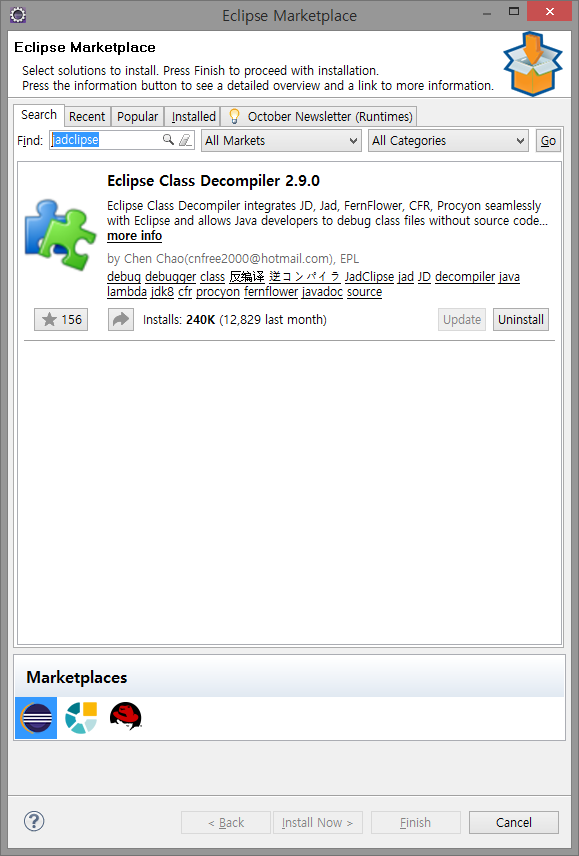
[Eclipse] 이클립스에 자바 클래스 디컴파일러 설치하는 법
기본적으로 확장자 Java파일은 메모장으로도 잘 열리지만 Class 파일은 컴파일된 상태라 열 수가 없다. 이럴 때 답답하다. “이거 안쪽이 어떻게 생겨먹은 메서드인겨…”라고 중얼거리게 된다.
보통 jd-gui 같은 디컴파일러를 쓴다. 다만 jd-gui 는 이클립스와 연동되지 않아 상당히 불편하다. 이클립스와 jd-gui, 이렇게 윈도우 2개를 동시에 켜고 번갈아 봐야하니까.
그런데 이클립스 자체에서 열 수 있는 방법이 있다. 기본 JDK 내의 Class 파일, 인터넷에서 다운받은 jar 내의 Class 파일 등을 이클립스 상에서 바로 바로 열어볼 수 있다.
(본 설명은 Eclipse Java EE IDE for Web Developers. Kepler Service Release 2 버전 기준입니다.)
1. 이클립스를 켠다.
2. 상단 메뉴의 Help – Eclipse Marketplace … 를 클릭한다.
3. Find (검색창) 란에 jadclipse 를 입력하여 검색한다.
4. Eclipse Class Decompiler 2.9.0 이 보일 것이다.
5. Intall 버튼을 누른다.
다음(Next), 다음, 다음… 그냥 쭉 다음을 눌러주는 다음 신공을 펼치면 알아서 설치되고 이클립스가 재기동된다.
이제 Class 파일을 열면 잘 열릴 것이다. 컨트롤+클릭 도 가능하다. 우왕 굳..
[JAVA] splitMulti 메서드
새로 만든 유용한 메서드. Split 과 기본적으로 같지만 딜리미터를 여러 개 사용 가능하다. 다른 점이라면 스트링 배열이 아니라 스트링 어레이리스트를 리턴해준다는 것 정도. 아래와 같이 쓰면 된다.
ex) ArrayList<String> inputList = StringUtil.splitMulti(inputText, “\r\n”, “\r”, “\n”, “;”);
———————————————————————-
|
/** ArrayList<String> resList = new ArrayList<String>(); if (fullStr == null || fullStr.length() == 0) { if (delimeters == null) { int deliCount = delimeters.length; StringBuffer contentStack = new StringBuffer(); int fullLen = fullStr.length(); boolean isDeli = false; for (int i = 0; i < fullLen; i++) { for (int k = 0; k < deliCount; k++) { if (i + oneDeli.length() > fullLen) { if (fullStr.substring(i, i + oneDeli.length()).equals(oneDeli)) { // oneDeli 로 자른다. if (!isDeli) { if (contentStack.length() > 0) { return resList; |
cos.jar
cos-26Dec2008.zip 파일 첨부하였습니다. 원래는 http://servlets.com/cos/ 에서 다운로드할 수 있습니다.
자바 유니코드 변환(encode, decode)
2016-11-14
인터넷에 돌아다니는 소스를 다소 수정하여 만들었음. by bb_
public static void main(String[] args) {
try {
System.out.println(encode(“동해물과 백두산이 마르고 닳도록,”));
System.out.println(decode(“\ub3d9\ud574\ubb3c\uacfc \ubc31\ub450\uc0b0\uc774 \ub9c8\ub974\uace0 \ub2f3\ub3c4\ub85d\u002c”));
System.out.println(decode(encode(“동해물과 백두산이 마르고 닳도록,”)));
}catch (Exception e) {
e.printStackTrace();
}
}
public static String decode(String unicodeStr) throws Exception {
StringBuffer str = new StringBuffer();
int i = -1;
char ch = 0;
String decodeStr = “”;
int nextBegin = -1;
while ((i = unicodeStr.indexOf(“\\u“)) > -1) {
if (i + 6 > unicodeStr.length()) {
// 유니코드 값이 길이가 4자리가 안된다면 변환 무시
decodeStr = “\\u” + unicodeStr.substring(i + 2);
nextBegin = unicodeStr.length();
} else {
try {
ch = (char)Integer.parseInt(unicodeStr.substring(i + 2, i + 6), 16);
decodeStr = String.valueOf(ch);
nextBegin = i + 6;
} catch (NumberFormatException e) {
// 유니코드 값이 16진수 포맷이 아니라면 변환 무시
decodeStr = “\\u” + unicodeStr.substring(i + 2, i + 6);
nextBegin = i + 6;
}
}
str.append(unicodeStr.substring(0, i));
str.append(decodeStr);
unicodeStr = unicodeStr.substring(nextBegin);
}
str.append(unicodeStr);
return str.toString();
}
public static String encode(String orgStr) throws Exception {
StringBuffer str = new StringBuffer();
int len = orgStr.length();
for (int i = 0; i < len; i++) {
if (((int)orgStr.charAt(i) == 32)) {
str.append(” “);
continue;
}
str.append(“\\u“);
String hexCode = Integer.toHexString((int)orgStr.charAt(i));
int space = 4 – hexCode.length();
for(int k=0; k<space; k++) {
str.append(“0”);
}
str.append(hexCode);
}
return str.toString();
}
유니코드 한자 정규식 (한자 포함되어 있는지 확인)
String target = “한자 포함되어 있는 문장 上海 “;
String regEx = “.*[\u2e80-\u2eff\u31c0-\u31ef\u3200-\u32ff\u3400-\u4dbf\u4e00-\u9fbf\uf900-\ufaff].*”;
if (target.matches(regEx)) {
System.out.println(“일치”);
} else {
System.out.println(“불일치”);
}
(참고 1) 유니코드 범위
http://blog.naver.com/bb_/220861227839
2E80 2EFF CJK Radicals Supplement 한중일 부수 보충
31C0 31EF CJK Strokes 한중일 한자 획
3200 32FF Enclosed CJK Letters and Months 한중일 괄호 문자
3400 4DBF CJK Unified Ideographs Extension A 한중일 통합 한자 확장-A
4E00 9FBF CJK Unified Ideographs 한중일 통합 한자
F900 FAFF CJK Compatibility Ideographs 한중일 호환용 한자
(참고 2)
// 원래는 [\u20000-\u2a6df\u2f800-\u2fa1f] 까지 포함되어 있었는데
// 역슬래시u + 5자리 유니코드는 일반적이지도 않고, (보통 역슬래시u + 4자리)
// 숫자랑 일반 알파벳이 섞여있어서, 5자리 유니코드는 뺐음.
20021 : !
20022 : “
20023 : #
20024 : $
20025 : %
20026 : &
20027 : ‘
20028 : (
20029 : )
20030 : 0
20031 : 1
20032 : 2
20033 : 3
20034 : 4
20035 : 5
20036 : 6
20037 : 7
20038 : 8
20039 : 9
20040 : @
20041 : A
20042 : B
20043 : C
20044 : D
20045 : E
20046 : F
20047 : G
20048 : H
20049 : I
20050 : P
20051 : Q
20052 : R
20053 : S
20054 : T
20055 : U
20056 : V
20057 : W
20058 : X
20059 : Y
20060 : `
20061 : a
20062 : b
20063 : c
20064 : d
20065 : e
20066 : f
20067 : g
20068 : h
20069 : i
20070 : p
20071 : q
20072 : r
20073 : s
20074 : t
20075 : u
20076 : v
20077 : w
20078 : x
20079 : y
유니코드 범위
|
처음 |
끝 | 영어 | 한국어 |
|---|---|---|---|
| 0000 | 007F | Controls and Basic Latin | 제어 문자와 라틴 기본 |
| 0080 | 00FF | Controls and Latin-1 Supplement | 제어 문자와 라틴 보충 |
| 0100 | 017F | Latin Extended-A | 라틴 확장-A |
| 0180 | 024F | Latin Extended-B | 라틴 확장-B |
| 0250 | 02AF | IPA Extensions | 국제 음성 기호 확장 |
| 02B0 | 02FF | Spacing Modifier Letters | 조정 문자 |
| 0300 | 036F | Combining Diacritical Marks | 조합 분음 기호(악센트) |
| 0370 | 03FF | Greek and Coptic | 그리스어와 콥트어 |
| 0400 | 04FF | Cyrillic | 키릴 자모 |
| 0500 | 052F | Cyrillic Supplementary | 키릴 자모 보충 |
| 0530 | 058F | Armenian | 아르메니아어 |
| 0590 | 05FF | Hebrew | 히브리어 |
| 0600 | 06FF | Arabic | 아랍어 |
| 0700 | 074F | Syriac | 시리아어 |
| 0750 | 077F | Arabic Supplement | 아랍어 보충 |
| 0780 | 07BF | Thaana | 타아나어 |
| 07C0 | 07FF | N’Ko | 은코 |
| 0900 | 097F | Devanagari | 데바나가리어 |
| 0980 | 09FF | Bengali | 벵골어 |
| 0A00 | 0A7F | Gurmukhi | 굴묵키어 |
| 0A80 | 0AFF | Gujarati | 구자라트어 |
| 0B00 | 0B7F | Oriya | 오리야어 |
| 0B80 | 0BFF | Tamil | 타밀어 |
| 0C00 | 0C7F | Telugu | 텔루구어 |
| 0C80 | 0CFF | Kannada | 칸나다어 |
| 0D00 | 0D7F | Malayalam | 말라얄람어 |
| 0D80 | 0DFF | Sinhala | 신할라어 |
| 0E00 | 0E7F | Thai | 타이어 |
| 0E80 | 0EFF | Lao | 라오어 |
| 0F00 | 0FFF | Tibetan | 티베트어 |
| 1000 | 109F | Myanmar | 미얀마어 |
| 10A0 | 10FF | Georgian | 그루지야어 |
| 1100 | 11FF | Hangul Jamo | 한글 자모 |
| 1200 | 137F | Ethiopic | 에티오피아어 |
| 1380 | 139F | Ethiopic Supplement | 에티오피아어 보충 |
| 13A0 | 13FF | Cherokee | 체로키어 |
| 1400 | 167F | Unified Canadian Aboriginal Syllabics | 통합 캐나다 원주민 소리 마디 |
| 1680 | 169F | Ogham | 오검 문자 |
| 16A0 | 16FF | Runic | 룬 문자 |
| 1700 | 171F | Tagalog | 타갈로그어 |
| 1720 | 173F | Hanunoo | 하누누어 |
| 1740 | 175F | Buhid | 부히드어 |
| 1760 | 177F | Tagbanwa | 타그반와어 |
| 1780 | 17FF | Khmer | 크메르어(캄보디아어) |
| 1800 | 18AF | Mongolian | 몽골어 |
| 1900 | 194F | Limbu | 림부 |
| 1950 | 197F | Tai Le | 타이 레 문자 |
| 1980 | 19DF | New Tai Lue | 새 타이 루에 |
| 19E0 | 19FF | Khmer Symbols | 크메르 기호 |
| 1A00 | 1A1F | Buginese | 부기 문자 |
| 1B00 | 1B7F | Balinese | 발리 문자 |
| 1D00 | 1D7F | Phonetic Extensions | 음성 부호 확장 |
| 1D80 | 1DBF | Phonetic Extensions Supplement | 음성 부호 확장 보충 |
| 1DC0 | 1DFF | Combining Diacritical Marks Supplement | 조합 분음 부호(악센트) 보충 |
| 1E00 | 1EFF | Latin Extended Additional | 라틴어 추가 확장 |
| 1F00 | 1FFF | Greek Extended | 그리스어 확장 |
| 2000 | 206F | General Punctuation | 일반 구두점 |
| 2070 | 209F | Superscripts and Subscripts | 위 첨자와 아래 첨자 |
| 20A0 | 20CF | Currency Symbols | 화폐 기호 |
| 20D0 | 20FF | Combining Diacritical Marks for Symbols | 조합 분음 부호(기호) |
| 2100 | 214F | Letterlike Symbols | 글자를 변형한 기호 |
| 2150 | 218F | Number Forms | 여러 가지 수 |
| 2190 | 21FF | Arrows | 화살표 |
| 2200 | 22FF | Mathematical Operators | 수학 연산자 |
| 2300 | 23FF | Miscellaneous Technical | 여러 가지 기술 기호 |
| 2400 | 243F | Control Pictures | 제어 문자 기호 |
| 2440 | 245F | Optical Character Recognition | 문자 인식(OCR) 기호 |
| 2460 | 24FF | Enclosed Alphanumerics | 괄호 문자 |
| 2500 | 257F | Box Drawing | 상자 그리기 기호 |
| 2580 | 259F | Block Elements | 네모 기호 |
| 25A0 | 25FF | Geometric Shapes | 도형 기호 |
| 2600 | 26FF | Miscellaneous Symbols | 여러 가지 기호 |
| 2700 | 27BF | Dingbats | 딩뱃 기호 |
| 27C0 | 27EF | Miscellaneous Mathematical Symbols-A | 여러 가지 수학 기호-A |
| 27F0 | 27FF | Supplemental Arrows-A | 화살표 보충-A |
| 2800 | 28FF | Braille Patterns | 점자 |
| 2900 | 297F | Supplemental Arrows-B | 화살표 보충-B |
| 2980 | 29FF | Miscellaneous Mathematical Symbols-B | 여러 가지 수학 기호-B |
| 2A00 | 2AFF | Supplemental Mathematical Operators | 수학 연산자 보충 |
| 2B00 | 2BFF | Miscellaneous Symbols and Arrows | 여러 가지 기호와 화살표 |
| 2C00 | 2C5F | Glagolitic | 글라골리틱 문자 |
| 2C60 | 2C7F | Latin Extended-C | 라틴 확장-C |
| 2C80 | 2CFF | Coptic | 콥트어 |
| 2D00 | 2D2F | Georgian Supplement | 그루지야어 보충 |
| 2D30 | 2D7F | Tifinagh | 티피나그 |
| 2D80 | 2DDF | Ethiopic Extended | 에티오피아어 보충 |
| 2E00 | 2E7F | Supplemental Punctuation | 구두점 보충 |
| 2E80 | 2EFF | CJK Radicals Supplement | 한중일 부수 보충 |
| 2F00 | 2FDF | KangXi Radicals | 강희자전 부수 |
| 2FF0 | 2FFF | Ideographic Description characters | 한자 생김꼴 지시 부호 |
| 3000 | 303F | CJK Symbols and Punctuation | 한중일 기호 및 구두점 |
| 3040 | 309F | Hiragana | 히라가나 |
| 30A0 | 30FF | Katakana | 가타카나 |
| 3100 | 312F | Bopomofo | 주음 부호 |
| 3130 | 318F | Hangul Compatibility Jamo | 호환용 한글 자모 |
| 3190 | 319F | Kanbun | 훈독 순서 지시 부호 |
| 31A0 | 31BF | Bopomofo Extended | 주음 부호 확장 |
| 31C0 | 31EF | CJK Strokes | 한중일 한자 획 |
| 31F0 | 31FF | Katakana Phonetic Extensions | 가타카나 음성 확장 |
| 3200 | 32FF | Enclosed CJK Letters and Months | 한중일 괄호 문자 |
| 3300 | 33FF | CJK Compatibility | 한중일 호환용 |
| 3400 | 4DBF | CJK Unified Ideographs Extension A | 한중일 통합 한자 확장-A |
| 4DC0 | 4DFF | Yijing Hexagram Symbols | 역경 6줄 기호 |
| 4E00 | 9FBF | CJK Unified Ideographs | 한중일 통합 한자 |
| A000 | A48F | Yi Syllables | 이(Yi) 소리 마디 |
| A490 | A4CF | Yi Radicals | 이(Yi) 부수 |
| A700 | A71F | Modifier Tone Letters | 어조 조정 문자 |
| A720 | A7FF | Latin Extended-D | 라틴 확장-D |
| A800 | A82F | Syloti Nagri | 실헤티 나가리 |
| A840 | A87F | Phags-Pa | 파스파 문자 |
| AC00 | D7AF | Hangul Syllables | 한글 소리 마디 |
| D800 | DBFF | High Surrogate Area | 상위 대체 영역 |
| DC00 | DFFF | Low Surrogate Area | 하위 대체 영역 |
| E000 | F8FF | Private Use Area | 사용자 영역 |
| F900 | FAFF | CJK Compatibility Ideographs | 한중일 호환용 한자 |
| FB00 | FB4F | Alphabetic Presentation Forms | 영문 표현꼴 |
| FB50 | FDFF | Arabic Presentation Forms-A | 아랍어 표현꼴-A |
| FE00 | FE0F | Variation Selectors | 모양 구별 문자 |
| FE10 | FE1F | Vertical Forms | 세로쓰기 모양 |
| FE20 | FE2F | Combining Half Marks | 조합용 반쪽 기호 |
| FE30 | FE4F | CJK Compatibility Forms | 한중일 호환용 꼴 |
| FE50 | FE6F | Small Form Variants | 작은꼴 변형 |
| FE70 | FEFF | Arabic Presentation Forms-B | 아랍어 표현꼴-B |
| FF00 | FFEF | Halfwidth and Fullwidth Forms | 전각/반각 모양 |
| FFF0 | FFFF | Specials | 특수 제어 문자 |
| 10000 | 1007F | Linear B Syllabary | 선상 B 음절 문자 |
| 10080 | 100FF | Linear B Ideograms | 선상 B 상형 문자 |
| 10100 | 1013F | Aegean Numbers | 에게(Aegean) 숫자 |
| 10140 | 1018F | Ancient Greek Numbers | 옛 그리스 숫자 |
| 10300 | 1032F | Old Italic | 옛 이탈리아 문자 |
| 10330 | 1034F | Gothic | 옛 고딕체 알파벳 |
| 10380 | 1039F | Ugaritic | 우가리트 문자 |
| 103A0 | 103DF | Old Persian | 옛 페르시아 문자 |
| 10400 | 1044F | Deseret | 데저렛 문자 |
| 10450 | 1047F | Shavian | 샤우 문자 |
| 10480 | 104AF | Osmanya | 오스마니아 문자 |
| 10800 | 1083F | Cypriot Syllabary | 키프로스 음절 문자 |
| 10900 | 1091F | Phoenician | 페니키아 문자 |
| 10A00 | 10A5F | Kharoshthi | 카로슈티 |
| 12000 | 123FF | Cuneiform | 쐐기 문자 |
| 12400 | 1247F | Cuneiform Numbers and Punctuation | 쐐기 문자 숫자·문장 부호 |
| 1D000 | 1D0FF | Byzantine Musical Symbols | 비잔틴 시대의 악보용 기호 |
| 1D100 | 1D1FF | Musical Symbols | 악보용 기호 |
| 1D200 | 1D24F | Ancient Greek Musical Notation | 고대 그리스 시대의 악보용 기호 |
| 1D300 | 1D35F | Tai Xuan Jing Symbols | 태현경 기호 |
| 1D400 | 1D7FF | Mathematical Alphanumeric Symbols | 수학식에서 쓰이는 알파벳 |
| 20000 | 2A6DF | CJK Unified Ideographs Extension B | 한중일 통합 한자 확장-B |
| 2F800 | 2FA1F | CJK Compatibility Ideographs Supplement | 한중일 호환용 한자 보충 |
| E0000 | E007F | Tags | 태그 |
| E0100 | E01EF | Variation Selectors Supplement | 모양 구별 문자 보충 |
| F0000 | FFFFF | Supplementary Private Use Area-A | 사용자 영역 보충-A |
| 100000 | 10FFFF | Supplementary Private Use Area-B | 사용자 영역 보충-B |
JQuery html의 tagName 얻기
제이쿼리 html 태그명 알아내는 법.
var targetTagName = $(“#certainId”).prop(“tagName”);
하면 된다.
예를 들어 <form id=”certainId”></form> 이면 “FORM”을 얻는다.
참고 :
var str = “FORM”;
str = str.toUpperCase(); // str == “FORM” 가 된다.
str = str.toLowerCase(); // str == “form” 가 된다.
jquery ajax 기초
function sendPost () {
var url = “test.jsp”;
var params= ” a=111&b=222″;
// 참고 : $( “form” ).serialize();
$.ajax({
type : “POST”,
url : url,
data : params,
success : function(result) {
alert(“결과 : ” + result);
},
// beforeSend : showRequest,
error : function(e){
alert(e.responseText);
}
});
}
자바 정규식 기초
String regEx = “.*”
– 모든 문자
String regEx = “[0-9][0-9][0-9][0-9][0-9]”;
– 숫자 5자리
String regEx = “^[0-9].*[0-9]$”;
– 숫자로 시작해서 숫자로 끝남
String regEx = “\\d{3}”;
– 숫자 3자리
String regEx = “\\d{1,5}”;
– 숫자 1자리 이상 5자리 이하
실제로 쓰는 방법.
String target = “분석이 필요한 스트링”;
String regEx = “.*”; // 일 때,
if (target.maches(regEx)) {
// 정규식 조건 충족
} else {
// 정규식 조건 미충족
}
// 위와 같이 쓰면 됨.
svn compare시 한글 깨질 경우 utf-8 변환법
window – preferences 에서
좌측 상단 텍스트 박스에 encoding 으로 검색한다.
좌측 메뉴의 General – Workspace 를 클릭하여
Text file encoding 을 UTF-8로 설정해준다.
document.oncontextmenu 와 마우스 우클릭
1. 마우스 우클릭 시 펑션 실행
자바스크립트에서 document.oncontextmenu 가 기본값(null)이면 마우스 우클릭 가능.
= function(){} 으로 펑션 대입하면 마우스 우클릭시 펑션 실행.
2. 마우스 우클릭 막기
마우스 우클릭 막으려면 함수를 대입하되 내용을 비워두면 됨.
혹은
function document.oncontextmenu() {
return false;
}
식으로 쓴다.
혹은
document.onselectstart = new function() {
return false;
}
식으로 쓴다.
3. 참고
function document.onselectstart() {
return false;
}
function document.ondragstart() {
return false;
}
톰캣 8.0 초기세팅 (Tomcat 8.0)
1. server.xml 에서 포트 변경.
<Connector connectionTimeout=”20000″ port=”8080″ protocol=”HTTP/1.1″ redirectPort=”8443″/>
포트를 8080 에서 80 으로 변경
localhost:8080 으로 접속해야 하는 것을 localhost 로 바로 접속할 수 있게 해준다.
2. server.xml 에서 Context 변경.
<Context docBase=”프로젝트명” path=”/프로젝트명” reloadable=”true” source=”org.eclipse.jst.jee.server:프로젝트명”/></Host>
위와 같이 쓰면 “localhost:포트번호/프로젝트명”이라고 주소 입력하였을 때 서블릿으로 연결된다.
<Context docBase=”프로젝트명” path=”/” reloadable=”true” source=”org.eclipse.jst.jee.server:프로젝트명”/></Host>
위와 같이 수정하면 “localhost:포트번호/”이라고 주소 입력하였을 때 서블릿으로 연결된다.
jdk7 다운로드
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
jdk8 다운로드
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
JDK는 자바 개발 도구(Java Development Kit)의 약자이다.
윈도우 정품인증 상태 확인 명령어
1. 시작 – 실행 – cmd
2. slmgr /dlv 입력 후 엔터
jsp 파일 업로드 참고 : request.getInputStream
public void doPost( HttpServletRequest req, HttpServletResponse resp ) throws Exception {
String reqContentType = req.getContentType();
System.out.println( “reqContentType : ” + reqContentType );
InputStream input = req.getInputStream();
ByteArrayOutputStream result = null;
PrintWriter writer = null;
try{
input = req.getInputStream();
result = new ByteArrayOutputStream();
byte[] buffer = new byte[1024]; // 한 번 읽을때마다 1024씩
int size=0;
while((size=input.read(buffer, 0, 1024))!=-1){
//-1 이 EOF
System.out.println(“size : ” + size);
result.write( buffer, 0, size );
}
// System.out.println( b.toString(“UTF-8”) );
// 폴더 만든다
File dir = new File( “c:/result/” );
if ( !dir.exists() ) {
dir.mkdir();
}
// 파일 만든다
File file = new File( “c:/result/aa.txt” );
if ( !file.exists() ) {
file.createNewFile();
}
// 내용 쓴다
writer = new PrintWriter( file );
writer.println( result.toString(“UTF-8”) );
writer.close();
} catch ( Exception e ) {
e.printStackTrace();
} finally {
try {
if ( input != null ){
input.close();
}
} catch ( Exception e ) {
input = null;
}
try {
if ( result != null ) {
result.close();
}
} catch ( Exception e ) {
result = null;
}
try {
if ( writer != null ) {
writer.close();
}
} catch ( Exception e ) {
writer = null;
}
}
}
자바 파일쓰기(Printwriter)
자바에서 Printwriter 객체를 이용하여 간단하게 파일을 쓸 수 있다.
File file = new File( “c:/aa.txt” );
Printwriter w = new PrintWriter( file );
w.println( “111” );
w.print( “222” );
w.close();
——————–
오전 1:25 2016-09-08
자바 파일쓰기(Printwriter) (2016/09/08 보완)
try {
// 폴더 만든다
File dir = new File( “c:/result/” );
if ( !dir.exists() ) {
dir.mkdir();
}
// 파일 만든다
File file = new File( “c:/result/aa.txt” );
if ( !file.exists() ) {
file.createNewFile();
}
// 내용 쓴다
writer = new PrintWriter( file );
writer.println( );
writer.close();
} catch ( Exception e ) {
e.printStackTrace();
} finally {
try {
if ( writer != null ) {
writer.close();
}
} catch ( Exception e ) {
writer = null;
}
}
1. 적당한 위치 (씨 드라이브의 foo 폴더라 해보자)에 폴더를 만든다.
2. 그 폴더 안에 텍스트 파일을 넣는다. 텍스트 파일 안에는 SQL문장만 잔뜩 써놓는다. 이 때 확장자는 sql로 한다. 예를 들면 파일명이 boo.sql 이라고 하자. SQL문 외에는 앞에 하이픈 두 개 (–)를 붙여 주석처리하자.
3. 시작 – 실행 – cmd 로 도스창을 켜고, cd 명령어를 이용해 만들어 놓은 foo 폴더로 이동하자.
4. sqlplus 아이디/비번@디비스키마이름
5. set heading off
헤더 필요 없다.
6. set pagesize 0
페이지 나누기 따위 없다.
7. set linesize 2000
가로 길이를 무지하게 넓게 잡아서 SQL결과가 엔터로 나뉘지 않도록 함
8. spool newfilename
9. @boo
그러니까, 골뱅이 뒤에 실행시킬 sql파일 이름을 쓴다.
10. spool off
하면 해당 폴더에 newfilename 이라는 이름으로 파일 써짐.
끝.
VBA/VB6 엔터를 구분자로 스트링 나누기 하기(Split), 배열의 크기(UBound, LBound)
엔터를 구분자로 Split 하기
Dim tArray
tArray = Split(str, vbCrLf, , vbTextCompare)
※ vbCrLf 은 엔터를 뜻한다. 캐리지 리턴, 라인 피드. 각각 나눠서 vbCr, vbLf 로도 각각 쓸 수 있다.
– 엑셀의 각 셀을 대상으로 vba 코딩을 하고 있다면, 엑셀은 vbCrLf 가 아니라 vbLf 를 인자값으로 넣어야 문자를 인식한다. 또한 vbTextCompare 옵션을 꼭 넣어줘야 인식한다.
– vbTextCompare 옵션은 대소문자를 구별하지 않겠다는 의미이다.
Split( 스트링, 바꿀 문자, 바꿀 갯수(미입력시 무제한을 나타내는 -1), 옵션 )
배열의 크기 얻기
Dim tArraySize
tArraySize = UBound(tArray) – LBound(tArray) + 1
예제
‘엔터가 포함된 스트링
Dim str
str = “내용1” + vbCrLf
str = str + “내용2” + vbCrLf
str = str + “내용3” + vbCrLf
str = str + “내용4”
‘배열
Dim tArray
‘스트링을 엔터를 기준으로 잘라서 배열화
tArray = Split(str, vbCrLf, , vbTextCompare)
‘배열 사이즈 구하기
Dim tArraySize
tArraySize = UBound(tArray) – LBound(tArray) + 1
‘배열 내용 출력
For i = 0 To tArraySize – 1
MsgBox (tArray(i))
Next i
java.lang.IllegalStateException: Cannot forward after response has been committed
위와 같은 에러 메시지를 봤을 때, 결론부터 말하면, 인크루드를 사용하자.
개인적으로 간단한 경량 웹 프레임워크를 만들고 있는데, 서블릿 단에서 위와 같은 에러가 발생했다. forward 하기 이전에 response의 Writer를 얻어 내용을 썼기 때문이다.
처음부터 하나씩 설명하면, 먼저 자바에서 HttpServlet을 상속한 어떤 서블릿이 doPost, doGet 메소드를 오버라이드한 상태라고 해보자. 이 때 보통은 doPost, doGet 내부에서 forward로 원하는 경로의 jsp로 이동시킨다.
예를 들면 아래와 같은 식이다.
RequestDispatcher dispatcher = req.getRequestDispatcher( “원하는/경로의/파일.jsp” );
dispatcher.forward( req, res );
그런데 이 jsp에, 내가 원하는 코드를 동적으로 합쳐서 jsp를 만들어보내고 싶다고 해보자. 나의 경우엔 에러메시지를 담아 보내거나, js변수들을 서버 단에서 만들어 보낼 작정이었다.
그렇다면 response에서 getWriter를 사용하여 Writer 객체를 얻고, write 함수로 내용을 넣으면 된다. 이것이 스프링에서의 @ResponseBody기능이다.
그런데 forward 전에, 아래와 같이 response에 무언가를 쓰는 행위를 했다고 하면 에러가 난다.
res.setCharacterEncoding(“UTF-8”);
res.getWriter().write(“<script> alert(‘Hello World’); </script>”);
res.getWriter().flush();
기본적으로 res에 write를 하고 flush를 하면 그것으로 끝난거지(그것이 페이지의 전부이다!), 이후에 forward를 쓸 수 없다. 그랬다간 java.lang.IllegalStateException: Cannot forward after response has been committed 에러가 난다.
스프링에서도 위와 같은 기능(기존 jsp에 원하는 코드를 동적으로 합쳐 내보내는 기능)은 지원하지 않기 때문에, 현재로서는 특정 컨트롤러 메소드에 @ResponseBody 어노테이션을 붙여놓고, ajax로 해당 부분을 불러오는 방법을 쓴다. 다시 말해서 jsp단 ajax 코드가 필수적이다.
나는 jsp에 일일히 코드가 들어가길 원하지 않았다. 그저 기존에 존재하는 jsp에, 원하는 에러메시지 스크립트를 합쳐서 보내고 싶었다. 안타깝게도 redirect를 써도 소용이 없다.
res.sendRedirect( “원하는/경로의/파일.jsp” );
라고 보내면 java.lang.IllegalStateException: Cannot call sendRedirect() after the response has been committed 에러가 뜬다. 마찬가지로 내용을 쓰고 나서 redirect를 해선 안된다. 더구나 sendRedirect는 forward와 달리 Attribute가 전달되지 않는다. 스프링으로 치면 모델 단에서 작업한 내용이 유실되는 셈이다. (그래서 스프링은 jsp 단에서 ajax로 한 번 더 부르는 방식을 사용한다.)
방법은 있다. include를 쓰는 것이다.
jsp 단에서 include를 부르느니 ajax와 차이가 없기 때문에, 서버 단에서 부른다. 아래와 같이 코딩하면 된다.
req.setAttribute(“myName”, “흑곰”); //테스트용 코드
res.setCharacterEncoding(“UTF-8”);
RequestDispatcher dispatcher = req.getRequestDispatcher( “원하는/파일의/경로.jsp” );
dispatcher.include( req, res );
res.getWriter().write(“<script> alert(‘Hello World’); </script>”);
res.getWriter().flush();
이렇게 include를 사용하면 된다. 이제 jsp에 동적으로 원하는 코드가 삽입된다. 해당 jsp에 ${myName}이라고 써넣고 어트리뷰트도 잘 넘어오는지 확인하자.
여기서 포인트는, Writer의 write와 flush를 뒤에 써준다는 것이다. 스스로 알아냄.
Failed to load the JNI shared library “jvm.dll”.

위와 같은 alert이 뜨면서 이클립스가 실행되지 않는 경우가 있다. 보통 내컴퓨터 우클릭 – 속성 – 설정변경 – 환경변수에서 시스템변수 JAVA_HOME과 시스템 변수 PATH를 다시 잡아주면 해결된다.
그러나 아무리 JAVA_HOME과 PATH를 다시 잡아도 이클립스가 해당 경로를 인식하지 못하는 경우가 있는데, 이 경우 아래와 같이 eclipse.ini 파일을 수정하면 된다.
주로 bit차이 때문에 일어나는 문제이다. 컴퓨터 내에 32비트와 64비트를 각각 깔아두고, 32비트 폴더 내의 jvm.dll이 존재하는 경로를 설정하여 해보고, 안되면 64비트 폴더 내의 jvm.dll이 존재하는 경로를 설정해서 시도해보자.

스프링에서 하둡 연동
현재 hadoop은 버전 2.7까지 나와있지만, 스프링에서는 높은 버전을 쓸 수 없다. 현재 hadoop-core 라이브러리(스프링에서 하둡을 바로 붙을 수 있도록 지원)가 1.2.1 까지 밖에 지원이 안된다. 하둡을 1.2.1로 깔고 그것에 나머지 하둡 에코시스템을 맞춰야하는 한계점이 있다.
1. hadoop-core
<!– http://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core –>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
2. app.xml
<?xml version=”1.0″ encoding=”UTF-8″?>
<beans xmlns=”http://www.springframework.org/schema/beans“
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance“
xmlns:aop=”http://www.springframework.org/schema/aop“
xmlns:context=”http://www.springframework.org/schema/context“
xmlns:hadoop=”http://www.springframework.org/schema/hadoop“
xmlns:p=”http://www.springframework.org/schema/p“
xsi:schemaLocation=”http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.2.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.1.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.1.xsd
http://www.springframework.org/schema/hadoop http://www.springframework.org/schema/hadoop/spring-hadoop.xsd“>
<!– 메모리 할당 –>
<context:annotation-config/>
<context:component-scan base-package=”com.com.*”></context:component-scan>
<!– 하둡 설정 –>
<!– private Configuration conf; –>
<hadoop:configuration id=”hadoopConf”>
fs.default.name=hdfs://localhost:9000
</hadoop:configuration>
</beans>
3. FileSystemMain.java
package com.sist.movie;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.stereotype.Component;
@Component(“fsm”)
public class FileSystemMain {
@Autowired
private Configuration conf;
public static void main(String[] args) {
//Component: 자동메모리 할당
//Autowired : 주소값 설정
try{
ApplicationContext app = new ClassPathXmlApplicationContext(“app.xml”);
FileSystemMain fm = (FileSystemMain) app.getBean(“fsm”);
FileSystem fs = FileSystem.get(fm.conf);
1) 로컬에서 하둡으로 파일 보내기
fs.copyFromLocalFile(new Path(“/home/sist/emp.csv”),
new Path(“/input/emp.csv”) );
//(2) 하둡에서 로컬로 파일 보내기
// fs.copyToLocalFile(new Path(“/input/emp.csv”),
// new Path(“./”) );
//(3) 하둡 내의 파일 삭제하기
//if( fs.exists(new Path(“/input/emp.csv”))){ //존재하면
// fs.delete(new Path(“/input/emp.csv”), true); //삭제
// 두번째 매개변수에 true를 주면 안쪽 파일까지 삭제되는 것
// ( 리눅스의 rm -rf와 같음. 하둡에서는 -rmr )
//}
fs.close();
System.out.println(“파일전송완료”);
}catch(Exception e){
System.out.println(“main error :”);
e.printStackTrace();
}
}
}
자바에서 하이브 사용하기
1. 하이브 스타트
설치된 하이브를 스타트 시킨다. 터미널에서 hive –service hiveserver 명령어를 치면 자바에서 접근할 수 있게 하이브를 기동시킨다.
참고)
(1) 하이브 설치 : http://blog.naver.com/bb_/220739646411
(2) 하이브 실행 : http://blog.naver.com/bb_/220739653295
2. 라이브러리 가져오기
maven 기준으로 가져와야 하는 라이브러리를 나열하겠다.
(1) Hive Query Language 0.9.0
<!– http://mvnrepository.com/artifact/org.apache.hive/hive-exec –>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.9.0</version>
</dependency>
(2) Hive Metastore 0.9.0
<!– http://mvnrepository.com/artifact/org.apache.hive/hive-metastore –>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>0.9.0</version>
</dependency>
(3) Hive Service 0.9.0
<!– http://mvnrepository.com/artifact/org.apache.hive/hive-service –>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service</artifactId>
<version>0.9.0</version>
</dependency>
(4) Hive Common 0.9.0
<!– http://mvnrepository.com/artifact/org.apache.hive/hive-common –>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>0.9.0</version>
</dependency>
(5) Hive JDBC 0.9.0
<!– http://mvnrepository.com/artifact/org.apache.hive/hive-jdbc –>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.9.0</version>
</dependency>
(6) JDO2 API 2.0
<!– http://mvnrepository.com/artifact/javax.jdo/jdo2-api –>
<dependency>
<groupId>javax.jdo</groupId>
<artifactId>jdo2-api</artifactId>
<version>2.0</version>
</dependency>
3. 테이블을 select해서 읽는 자바 소스
package com.com.hive;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class HiveMain {
public static void main(String[] args) {
Connection conn = null;
ResultSet rs = null;
try{
String driver = “org.apache.hadoop.hive.jdbc.HiveDriver”;
Class.forName(driver);
String url = “jdbc:hive://localhost:10000/default”;
//기본 포트가 10000 번이고, 기본데이터베이스 이름이 defualt 임.
String id = “hive”;
String pw = “hive”;
conn = DriverManager.getConnection(url, id, pw);
String sql = “SELECT * FROM dept”;
Statement stmt = conn.createStatement();
rs = stmt.executeQuery(sql);
while(rs.next()){
String col1 = rs.getString(1);
String col2 = rs.getString(2);
String col3 = rs.getString(3);
System.out.println( col1 + “/” + col2 + “/” + col3 );
}
rs.close();
conn.close();
}catch(Exception ex){
System.err.println(“main error :”);
ex.printStackTrace();
}finally {
try{
if( rs != null ){
rs.close();
}
}catch(Exception ex){
rs = null;
}
try{
if( conn != null ){
conn.close();
}
}catch(Exception ex){
conn = null;
}
}
}
}
하이브(hive) 테이블 만들기
1, 하이브 설치
http://blog.naver.com/bb_/220739646411
2. 하이브 실행
터미널을 켜서 hive 라고 친다.
3. 하이브로 들어왔으면 show tables; 이라고 쳐서 OK 값이 나와야 정상.
에러가 떨어지면 읽어보고 설정파일을 수정한다. 패스워드와 아이디가 맞는지 확인해본다.
4. 테이블 만들기
create table dept(dname string,loc string,deptno int) 엔터
row format delimited fields terminated by ‘,’; 엔터
load data local inpath ‘/home/sist/dept.csv’ overwrite into table dept; 엔터
하면 dept.csv파일(쉼표를 구분자로 한 파일) 을 읽어서 테이블로 만든다.
5. 테이블 조회
select * from dept;
6. 하이브 종료
exit; 로 종료한다.
7. 참고) 하이브 스타팅
자바에서 접근할 수 있게 기동시킬 수 있다.
hive –service hiveserver
하이브 설치 기초(hive-0.9.0)
1. mysql 설치
(1) mysql 설치 : sudo apt-get install mysql-server
(2) sql 접속 : mysql -u root -p
(3) 권한주기 : grant all privileges on *.* to ‘hive’@localhost identified by ‘hive’;
(4) 빠져나와서 하이브 유저로 sql 접속 : mysql -u hive -p
hive> 로 접속되면 됨.
2. 구글에서 hive-0.9.0.tar.gz 검색해서 다운로드
3. 해당 파일 압축 풀고 로컬 폴더로 이동시키기
/usr/local/hive-0.9.0
4. 환경설정 파일 수정
sudo nano /etc/environment
PATH 뒤쪽에 내용추가. (따옴표 안쪽 부분에 콜론을 붙이고 이어 쓰면 됨)
PATH = “……..:/usr/local/hive-0.9.0/bin”
HIVE_HOME=”/usr/local/hive-0.9.0″
5. Hive설정 파일 수정
폴더 경로 /usr/local/hive-0.9.0/conf 로 간다.
(1) hive-env.sh.template 을 복사 떠서 hive-env.sh 라는 이름으로 만든다.
(2) hive-default.xml.template 를 복사 떠서 hive-site.sh 라는 이름으로 만든다.
6. hive-env.sh 파일 수정하기
(1) #export HADOOP_HEAPSIZE=1024 를 찾아서
앞의 샵 떼고 export HADOOP_HEAPSIZE=4096 로 변경
(2) # HADOOP_HOME=${bin}/../../hadoop 을 찾아서
앞의 샵 떼고 HADOOP_HOME=/usr/local/hadoop-1.2.1 로 변경 (실제 하둡 경로를 지정)
(3) # export HIVE_CONF_DIR= 을 찾아서
앞의 샵 떼고 export HIVE_CONF_DIR=/usr/local/hive-0.9.0/conf 로 변경
6. hive-site.xml 수정하기
컨트롤 F키를 이용해서 특정 문구를 찾고 변경하는 작업을 한다.
(1) <property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
를 찾아서
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore_db?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
로 변경
(2) <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
를 찾아서
<property>
<name>hive.stats.jdbcdriver</name>
<value>com.mysql.jdbc.Driver</value>
<description>The JDBC driver for the database that stores temporary hive statistics.</description>
</property>
로 변경
(3) <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value> #이 부분에 아이디 넣기
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value> #이 부분에 비밀번호 넣기
<description>password to use against metastore database</description>
</property>
를 찾아서 아이디 밸류와 패스워드 밸류를 변경
(4) <property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
의 밸류값을 기억하기. 변경할건 없음.
7. 터미널 들어가서 세팅
hadoop dfs -mkdir /tmp
hadoop dfs -mkdir /user/hive/warehouse
hadoop dfs -chmod g+w /user/hive/warehouse
hadoop dfs -chmod g+w /tmp
8. mysql-connector-java-5.1.22.jar 을 받아서
/usr/local/hive-0.9.0/lib 안에 붙여넣기한다.
9. 하이브 실행
터미널에 source /etc/environment 라고 친다.
터미널에서 hive라고 친다.
아래처럼 나오면 실행되는 것이다.
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
Logging initialized using configuration in jar:file:/usr/local/hive-0.9.0/lib/hive-common-0.9.0.jar!/hive-log4j.properties
Hive history file=/tmp/sist/hive_job_log_sist_201606181517_383526935.txt
hive>
주키퍼 설치 기초(zookeeper-3.3.6)
1. 구글에서 zookeeper-3.3.6.tar.gz 검색해서 다운로드
2. 해당 파일 압축 풀고 로컬 폴더로 이동시키기
/usr/local/zookeepr-3.3.6
3. 환경설정 파일 수정
sudo nano /etc/environment
PATH 뒤쪽에 내용추가.
PATH = “……..:/usr/local/zookeeper-3.3.6/bin”
ZOOKEEPER_HOME=”/usr/local/zookeeper-3.3.6″
4. /home/hadoop/zk_data 폴더 생성
5. zk_data폴더 안에 myid 라는 파일 생성
vi myid 해서 안의 내용은 ‘1’ 딱 한 글자만 주고 저장(wq!)
6. conf파일 수정
/usr/local/zookeeper-3.3.6/conf 폴더 안의 zoo-sample.cfg파일 수정하기
(1) dataDir=/home/hadoop/zk_data 로 수정
(2)맨 아래 줄에 (clientPort=2181 아래줄) server.1=localhost:2888:3888 라고 입력 후 저장
(3) 파일명을 zoo-sample.cfg에서 zoo.cfg로 변경하기
7. 주키퍼 서버 실행
cd 해서 홈으로 온 다음
zkServer.sh start
8. 주키퍼 클라이언트 실행
zkCli.sh start
하둡 기동시 Namenode나 Datanode 올라오지 않을 때
하둡 기동하다 보면 열 받는 때가 한 두번이 아니다. start-all.sh 명령어로 하둡을 처음 기동한 후 jps 라는 명령어를 치면 기본적으로 아래 6가지의 프로세스가 떠 있어야 한다.
TaskTracker, JobTracker, NameNode, DataNode, SecondaryNameNode, Jps
그런데 stop-all.sh 로 하둡을 껐다가 다음에 다시 start-all.sh 을 하면 5개만 올라오는 경우가 있다. 주로 Namenode가 없거나 Datanode가 없는 경우다. 단지재기동, 껐다 켰을 뿐인데 하둡이 깨져버리는(?) 현상이 잦다. 개인적으로 하둡을 사용할 때 가장 불만스러운 부분이다.
1. 작업 대상 폴더가 잘못된 경우
우선 하둡 작업을 하는 대상 폴더들의 위치를 아래와 같이 가정한다.
/home/hadoop/hdfs/data – 데이터노드용 폴더. hdfs-site.xml 에서 설정.
/home/hadoop/hdfs/name – 네임노드용 폴더. hdfs-site.xml 에서 설정.
/home/hadoop/hdfs/mapred – 맵리듀스용 폴더. 분석 결과를 모아놓는다. mapred-site.xml 에서 설정.
/home/hadoop/hdfs/temp – 임시 폴더. 공통으로 사용한다. core-site.xml 에서 설정.
이 때 각 xml 에서 작업 폴더의 주소를 존재하지 않거나 잘못된 주소로 설정할 경우 에러가 난다.
2. jps를 쳤을 때 Namenode 올라오지 않을 경우 해결
대표적인으로 20ms 이내에 기동했던 하둡을 끄고 재기동하는 경우에 네임노드가 올라오지 않을 수 있다고 한다. 아니, 잘 꺼졌다고 나온 후 다시 킨건데 그게 오류의 원인이 된다니(…) 앞으로는 잘 껐더라도 조심조심(?) 켜자.(…)
우선 stop-all.sh 으로 하둡을 끈다. 터미널에서 hadoop namenode -format 을 쳐서 네임 노드를 초기화시킨 후, start-all.sh로 하둡을 재기동한다.
3. jps를 쳤을 때 Datanode 올라오지 않는 경우 해결
여러가지 이유가 있다. 우선 stop-all.sh 으로 하둡을 끈다.
데이터를 저장하는 대상 폴더(사람마다 이름을 다르게 지정했을 테지만 보통 data, temp 등)들를 다 지우고, 해당 폴더들을 다시 생성한 후 start-all.sh로 다시 기동하면 된다.
4. 기타 문제들 : 로그 파일을 통한 해결
앞서와 같은 방법으로 해도 문제가 해결되지 않을 수 있다. 가장 좋은 방법을 로그를 보고 해결하는 것이다.
하둡 기동시에(start-all.sh 를 입력했을 때) 보통 아래와 같이 로그 파일에 대한 정보가 나온다.
starting namenode, logging to /usr/local/hadoop-1.2.1/logs/hadoop-sist-namenode-sist.out
localhost: starting datanode, logging to /usr/local/hadoop-1.2.1/logs/hadoop-sist-datanode-sist.out
localhost: starting secondarynamenode, logging to /usr/local/hadoop-1.2.1/logs/hadoop-sist-secondarynamenode-sist.out
starting jobtracker, logging to /usr/local/hadoop-1.2.1/logs/hadoop-sist-jobtracker-sist.out
localhost: starting tasktracker, logging to /usr/local/hadoop-1.2.1/logs/hadoop-sist-tasktracker-sist.out
이 후 jps를 쳐서 datanode가 뜨지 않았다면 cat을 이용해 해당 로그 파일을 읽으면 된다. 단, out확장자가 아니라 log 확장자의 파일을 봐야 한다.
그러니까 cat /usr/local/hadoop-1.2.1/logs/hadoop-sist-datanode-sist.out 이 아니라, cat /usr/local/hadoop-1.2.1/logs/hadoop-sist-datanode-sist.log 라고 치면 된다.
로그에 떨어지는 대표적인 상황 몇 개를 보자.
4-1. 네임스페이스 아이디 불일치
2016-06-18 10:18:49,167 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Incompatible namespaceIDs in /home/hadoop/hdfs/data: namenode namespaceID = 1686483618; datanode namespaceID = 178888247
현재 네임노드의 네임스페이스 아이디와 데이터노드의 네임스페이스 아이디가 일치하지 않는다고 나오고 있다. 이 때는 (1)하둡 종료(stop-all.sh) (2)작업대상 폴더들 삭제하고 다시 생성(rm명령어, mkdir명령어) (3)네임노드 초기화(hadoop namenode -format) (4)하둡 재기동(start-all.sh) 순으로 진행하면 된다.
네임노드 초기화시에 네임스페이스 아이디를 서로 맞춰준다.
4-2. 권한 문제
2016-06-18 11:08:07,832 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Invalid directory in dfs.data.dir: Incorrect permission for /home/hadoop/hdfs/data, expected: rwxr-xr-x, while actual: rwxrwxrwx
2016-06-18 11:08:07,832 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: All directories in dfs.data.dir are invalid.
작업대상 폴더들의 권한을 ( data, name, mapred, temp) 755 로 줘야 하는 문제다. 해당 폴더경로로 이동해서 chmod 755 * 을 주면 된다. 권한이 너무 높아도 안되고(777) 너무 낮아도 안되는 것 같다.